Cuando Azure Functions dejó de tener sentido en Kubernetes
Durante bastante tiempo usamos Azure Functions para resolver muchos procesos dentro de nuestros proyectos. Tenía sentido. Si necesitábamos exponer algo por HTTP, una Function. Si había un evento de Event Grid, una Function. Si llegaba un mensaje por Service Bus, otra Function. Si algo tenía que ejecutarse cada cierto tiempo, Timer Trigger.
Ese modelo funciona muy bien cuando realmente estás usando Azure Functions como producto gestionado de Azure.
Pero el contexto cambió.
El proyecto se movió a Kubernetes. Ya no estábamos desplegando esas piezas como recursos nativos de Azure Functions, sino como contenedores dentro de AKS. Y ahí empezó la pregunta incómoda: si todo corre como imagen Docker dentro de Kubernetes, ¿de verdad necesitamos seguir cargando el runtime de Azure Functions para cada caso?
La respuesta, en nuestro caso, fue no.
No porque Azure Functions sea malo. Al contrario, sigue siendo una herramienta muy buena. El problema era otro: dentro de Kubernetes, varias de esas Functions ya no estaban aprovechando lo suficiente del modelo serverless como para justificar el runtime adicional, el acoplamiento y la complejidad operativa.
El problema no era Azure Functions, era el contexto
Azure Functions brilla cuando te quita trabajo operativo: triggers, bindings, escalado, integración con el portal, diagnóstico, despliegue sencillo y modelo serverless.
Pero cuando lo llevas a Kubernetes, la conversación cambia.
Microsoft documenta que puedes ejecutar contenedores de Azure Functions en Kubernetes, incluso usando KEDA para escalado basado en eventos. Pero también deja claro que ese escenario tiene soporte comunitario o de mejor esfuerzo, y que el equipo queda responsable de mantener sus propios contenedores de Functions dentro del clúster.
Además, si usas imágenes custom de Azure Functions, también tienes que mantener la imagen base actualizada. Microsoft publica actualizaciones periódicas del runtime y de seguridad, pero si tu contenedor no se reconstruye y redespliega, te puedes quedar corriendo sobre una base vieja.
Entonces, visto fríamente, estábamos pagando varias capas:
- Kubernetes.
- Nuestra imagen Docker.
- El runtime de Azure Functions.
- Las extensiones y bindings de Functions.
- La lógica real de negocio.
Y en muchos casos la capa de Functions ya no era la que estaba aportando más valor.
La conversión que hicimos
La migración no fue un “reescribamos todo”. Fue más bien traducir cada tipo de Function a la primitiva que mejor encajaba en Kubernetes.
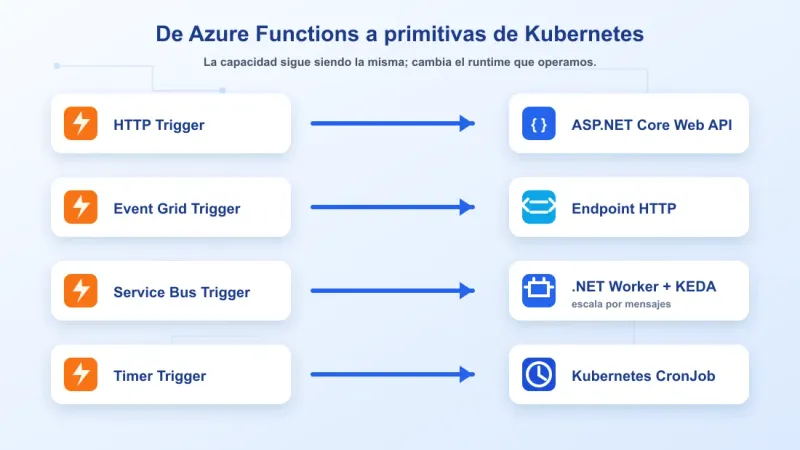
La equivalencia quedó más o menos así:
| Antes | Después |
|---|---|
| HTTP Trigger | ASP.NET Core Web API |
| Event Grid Trigger | Endpoint HTTP en Web API |
| Service Bus Trigger | Worker o consola .NET usando Azure.Messaging.ServiceBus |
| Timer Trigger | Kubernetes CronJob |
Esto parece un cambio pequeño, pero operacionalmente cambia bastante.
Un HTTP Trigger de Functions y un endpoint de Web API pueden resolver lo mismo desde fuera: reciben una petición y responden. Pero si el resto del sistema ya vive en ASP.NET Core, si el pipeline ya está preparado para APIs, si el monitoreo ya mira deployments y pods, entonces convertirlo en Web API reduce fricción.
Con Event Grid pasó algo parecido. Si usas el trigger nativo, Azure Functions te resuelve parte de la integración. Al pasarlo a Web API, tienes que implementar el endpoint de validación de la suscripción y procesar el payload. Pero en la práctica no fue una complicación enorme: es recibir el evento de validación, responder el validationCode y luego manejar los eventos reales.
Y hay una ventaja muy concreta: un endpoint HTTP normal es más fácil de probar, versionar, simular y automatizar dentro de un equipo que ya trabaja con APIs.
Service Bus: menos acoplamiento y más control
El caso de Service Bus fue uno de los más interesantes.
Con Azure Functions, el binding de Service Bus te da muchas cosas listas: concurrencia, auto-complete, renovación de locks, manejo del mensaje y configuración vía host.json. Eso es cómodo. Pero también te acopla al modelo de extensiones de Functions.
Al migrarlo a una aplicación .NET normal, pudimos usar directamente la librería nativa:
var processor = client.CreateProcessor("orders", new ServiceBusProcessorOptions{ AutoCompleteMessages = false, MaxConcurrentCalls = 8});
processor.ProcessMessageAsync += async args =>{ await ProcessOrder(args.Message); await args.CompleteMessageAsync(args.Message);};
processor.ProcessErrorAsync += args =>{ logger.LogError(args.Exception, "Error procesando mensaje de Service Bus"); return Task.CompletedTask;};
await processor.StartProcessingAsync();Esto no significa que desaparezca la responsabilidad. Al contrario: ahora tienes que entender mejor cómo procesas mensajes, cuándo completas, cuándo abandonas, cómo manejas errores y cuánta concurrencia permites.
Pero también ganas control.
Ya no dependes tanto de la versión del binding de Azure Functions ni del runtime para usar las capacidades del SDK. Puedes usar directamente Azure.Messaging.ServiceBus, actualizarlo con el ritmo del proyecto y modelar el worker como una aplicación .NET normal.
Para mí, ese punto es importante. Si ya estás en Kubernetes, muchas veces prefiero una aplicación explícita, aburrida y fácil de ejecutar, que una abstracción que fue muy útil en Azure Functions pero que dentro del clúster empieza a sentirse como una capa de más.
Eso sí, una cosa es el ejemplo mínimo y otra producción. En un worker real hay que cuidar graceful shutdown, CancellationToken, StopProcessingAsync, renovación de locks, DLQ, backoff y trazabilidad por mensaje. Azure Functions te escondía parte de esa complejidad; al salirte del runtime, esa responsabilidad vuelve a ser tuya.
KEDA cambió la conversación
La migración a consola o worker no significó dejar procesos prendidos todo el día esperando mensajes.
Aquí entró KEDA.
En vez de tener una Function o un worker permanentemente vivo escuchando una cola, usamos escalado basado en la cantidad de mensajes. KEDA puede mirar una cola o suscripción de Azure Service Bus y levantar pods cuando hay trabajo pendiente. Cuando no hay mensajes, puede volver a cero.
Ese cambio fue clave.
Porque ahí la optimización ya no fue solo conceptual. También fue operativa: menos consumo, menos pods activos sin necesidad y mejor alineación con la carga real.
Un ejemplo simplificado de la idea sería este:
apiVersion: keda.sh/v1alpha1kind: ScaledObjectmetadata: name: order-workerspec: scaleTargetRef: name: order-worker minReplicaCount: 0 maxReplicaCount: 10 triggers: - type: azure-servicebus metadata: queueName: orders namespace: my-servicebus-namespace messageCount: "5"No estoy diciendo que esta sea la única forma correcta. Puedes usar ScaledObject, ScaledJob o un modelo distinto según el tipo de procesamiento. El punto es otro: Kubernetes ya tenía una forma natural de expresar ese comportamiento, sin necesidad de mantener el runtime de Functions como intermediario.
Timer Trigger vs CronJob
Los Timer Trigger también fueron una conversión natural.
Si algo se ejecutaba cada cierto tiempo, lo movimos a Kubernetes CronJob. Otra vez, no porque Timer Trigger sea malo. Simplemente, si el despliegue, monitoreo y ejecución ya están en Kubernetes, un CronJob se entiende rápido:
apiVersion: batch/v1kind: CronJobmetadata: name: daily-reportspec: schedule: "0 3 * * *" concurrencyPolicy: Forbid jobTemplate: spec: template: spec: restartPolicy: OnFailure containers: - name: daily-report image: myregistry.azurecr.io/daily-report:1.0.0Aquí también hay que ser honestos: un CronJob no es exactamente lo mismo que un Timer Trigger. Kubernetes tiene su propia semántica de concurrencia y sus propios matices. La propia documentación advierte que, bajo ciertas circunstancias, un CronJob puede crear dos Jobs o ninguno. Por eso conviene diseñar estos procesos como idempotentes y pensar en concurrencyPolicy, reintentos, ventanas perdidas y observabilidad.
Pero como modelo operativo, encajaba mejor con el nuevo contexto.
El beneficio más visible: imágenes más pequeñas
Otro beneficio importante fue el tamaño de las imágenes.
Cuando partes de una imagen de Azure Functions, no solo llevas tu código. También llevas lo necesario para ejecutar el runtime de Functions. Eso tiene sentido si quieres ejecutar Functions. Pero si al final tu proceso es una Web API, un worker o una consola, puedes partir de una imagen base más ajustada al caso real.
Eso reduce peso, superficie y tiempos asociados al ciclo de build y despliegue.
No siempre el tamaño de la imagen es el problema principal. Pero cuando tienes muchos procesos pequeños, esa diferencia se acumula.
Lo que ganamos
Al final, la mejora no vino de una sola cosa. Vino de sumar varias decisiones pequeñas:
- Menos runtime innecesario dentro de AKS.
- Imágenes Docker más pequeñas y enfocadas.
- Menor acoplamiento a bindings y extensiones de Azure Functions.
- Uso directo de librerías .NET como
Azure.Messaging.ServiceBus. - Mejor testabilidad en endpoints HTTP y Event Grid.
- CronJobs expresados como recursos nativos de Kubernetes.
- Escalado con KEDA basado en mensajes reales.
- Un modelo operativo más uniforme para el equipo.
Y esto último pesa mucho. A veces la optimización no es solo CPU o memoria. A veces la optimización es que el equipo entienda mejor lo que está desplegando, cómo probarlo y cómo diagnosticarlo cuando falla.
Lo que tuvimos que asumir
Migrar fuera de Azure Functions también nos obligó a hacer explícitas varias responsabilidades: manejo de retries, idempotencia, graceful shutdown, DLQ, health checks, métricas por mensaje, configuración de KEDA y mantenimiento de manifests. No fue solo quitar runtime; fue mover responsabilidad desde el framework hacia nuestra arquitectura.
Para algunos equipos eso es una mala noticia. Para otros, especialmente si ya operan AKS con naturalidad, es simplemente volver explícita una complejidad que ya existía.
Dónde no haría esta migración
No convertiría esto en una regla universal.
Si estás usando Azure Functions como producto gestionado, con consumo serverless, integración directa con Azure, bindings que te ahorran código y poco interés en administrar infraestructura, Azure Functions sigue siendo una excelente opción.
Tampoco migraría solo por moda. Si tu Function App funciona bien, el equipo la entiende y no tienes dolor operativo, moverla a Kubernetes puede ser simplemente cambiar un problema por otro.
Y aquí hay un punto intermedio que sí vale la pena mencionar: Azure Container Apps. Si el objetivo es seguir usando Azure Functions en contenedores sin operar directamente el clúster, Azure Container Apps puede ser una alternativa más natural. En nuestro caso, el punto era distinto: el sistema ya estaba operando sobre AKS, con pipelines, observabilidad y despliegues Kubernetes existentes.
Pero cuando ya estás en AKS, ya tienes pipeline de contenedores, ya usas observabilidad de Kubernetes y ya estás pagando el costo de operar el clúster, vale la pena hacerse la pregunta:
¿Azure Functions sigue aportando suficiente valor aquí, o solo quedó como una capa heredada?
En nuestro caso, la respuesta fue clara.
Migrar a Web APIs, workers y CronJobs nos dio más control, menos acoplamiento y una forma más natural de operar dentro de Kubernetes. No fue una pelea contra Azure Functions. Fue aceptar que una herramienta excelente en un contexto puede dejar de ser la mejor decisión en otro.
Si quieres seguir aprendiendo sobre estos temas te invito a ver mis otras publicaciones.
Referencias
- Linux container support in Azure Functions
- Azure Container Apps hosting of Azure Functions
- Azure Service Bus bindings for Azure Functions
- ServiceBusProcessorOptions.MaxConcurrentCalls
- Message transfers, locks, and settlement in Azure Service Bus
- Receive Azure Event Grid events to an HTTP endpoint
- Azure Service Bus scaler en KEDA
- Kubernetes CronJob
